
简单原理来说分3步:
步骤1:在开始语音识别乊前,把首尾端的静音切除,降低对后续步骤造成的干扰,操作称为VAD。
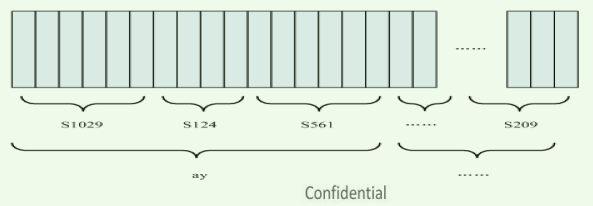
步骤2:静音切除后,要进行分帧,就是把声音切开成小段,每小段称为一帧。
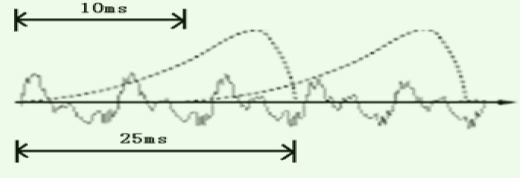
步骤3:分帧后,提取波形声学特征(例如MFCC )。每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。通过“声学模型” (语音训练得到) 的参数,就可以知道帧和状态对应的概率(语言模型),使用隐马尔可夫模型(HMM),构建一个状态网络,从状态网络中寻找不声音最佳匹配的路径,最终解码语音识别的结果。
详细的一个语音识别系统则如下:
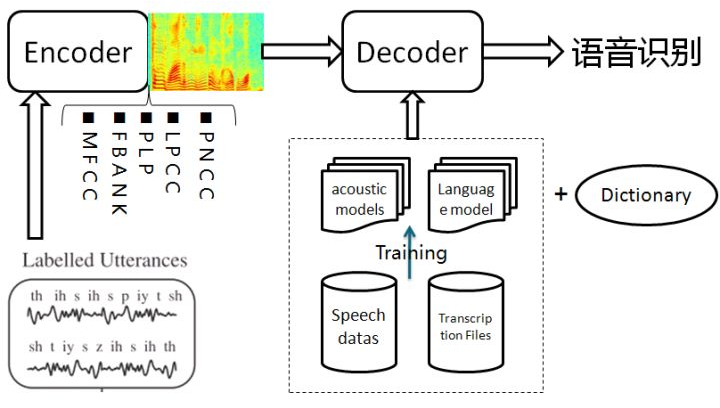
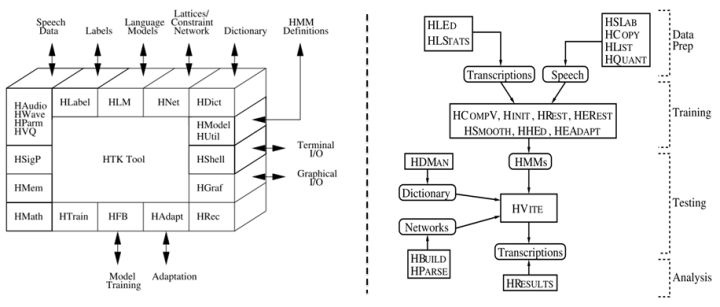
1.语音识别系统的一般架构如左图,分训练和解码两阶段。训练,即通过大量标注的语音数据训练声学模型,包括GMM-HMM、DNN-HMM和RNN+CTC等;解码,即通过声学模型和语言模型将训练集外的语音数据识别成文字。目前常用的开源工具有HTK Speech Recognition Toolkit,Kaldi ASR以及基于Tensorflow(speech-to-text-wavenet)实现端到端系统。我以古老而又经典的HTK为例,来阐述语音识别领域涉及到的概念及其原理。HTK提供了丰富的语音数据处理,以及训练和解码的工具。
2.语音识别,分为孤立词和连续词语音识别系统。早期,1952年贝尔实验室和1962年IBM实现的都是孤立词(特定人的数字及个别英文单词)识别系统。连续词识别,因为不同人在不同的场景下会有不同的语气和停顿,很难确定词边界,切分的帧数也未必相同;而且识别结果,需要语言模型来进行打分后处理,得到合乎逻辑的结果。
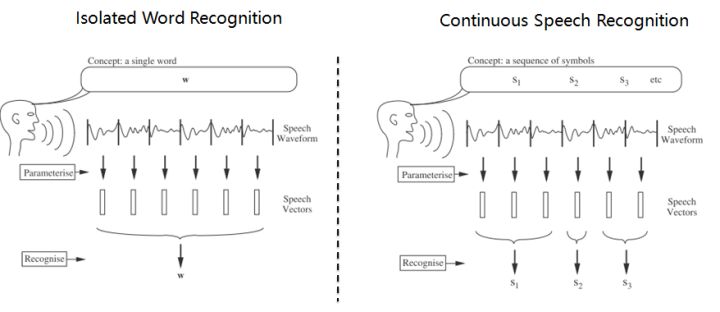
3.以孤立词识别为例,能够很好地阐述语音识别的流程级相关概念。假如对词进行建模,在训练阶段学习每个模型的参数;在识别阶段,计算输入语音序列在每个模型的得分(概率值),最高分者获胜。但是,任何语言里的常用单词都以千计,学习数以千计的模型不仅需要庞大的语料库,还需要漫长的迭代时间。此外,汉语还分有调无调,模型数量又成倍增加。
因此,通常对音素建模,然后由音素组合成单词;将极大地降低模型数量,提高训练和解码效率。对英语,常用的音素集是卡内基梅隆大学提供的一套由39个音素构成的音素集(参见The CMU Pronouncing Dictionary)。对汉语,一般用23个声母和24个韵母作为音素集。
4. 采用隐马尔可夫模型(Hidden Markov Model,HMM)对音素建模。1970年,普林斯顿大学的Lenny Baum发明HMM模型,并于20世纪80年代引入到语音识别领域,取得里程碑性的突破。HMM的通俗讲解参见简单易懂的例子解释隐马尔可夫模型。
如上左图,每个音素用一个包含6个状态的HMM建模,每个状态用高斯混合模型GMM拟合对应的观测帧,观测帧按时序组合成观测序列。每个模型可以生成长短不一的观测序列,即一对多映射。训练,即将样本按音素划分到具体的模型,再学习每个模型中HMM的转移矩阵和GMM的权重以及均值方差等参数。

5.参数学习,通过Baum-Welch算法,采用EM算法的思想。因此,每个模型需要初始化,GMM一般采用每个模型对应所有样本的均值和方差。硬分类模式,即计算每帧对应每个状态的GMM值,概率高者获胜;而软分类模式,即每帧都以对应概率值属于对应的状态,计算带权平均。
其中,表示t时刻的帧属于状态j的概率。用动态规划前向后向算法计算。
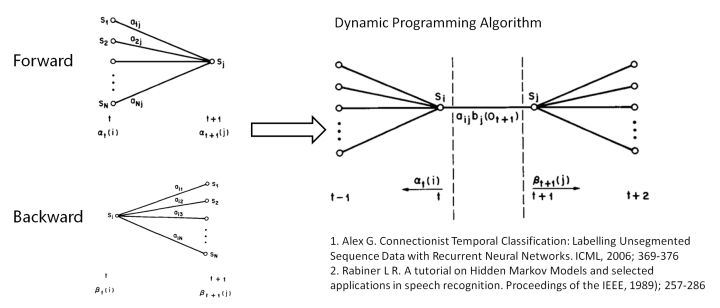

另外,转移矩阵参数的更新策略:
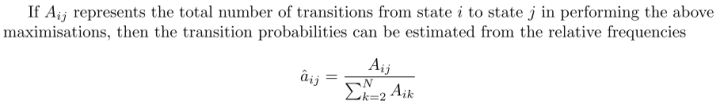
值得一提,CTC算法的核心就是前向后向算法。
6. 解码,采用Viterbi算法。模型在时间轴上展开的网络中贪婪地寻找最优路径问题,当前路径的联合概率值即为模型得分,选择最优模型,识别出音素,再查找字典,组装成单词。取对数可以避免得分过小的问题。
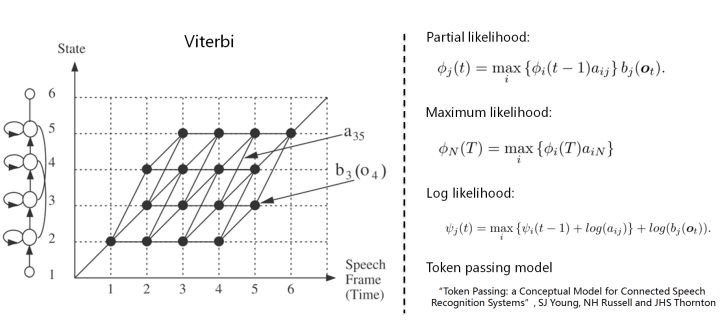
THK基于Token Passing实现Viterbi算法,用链表记录识别路径信息:
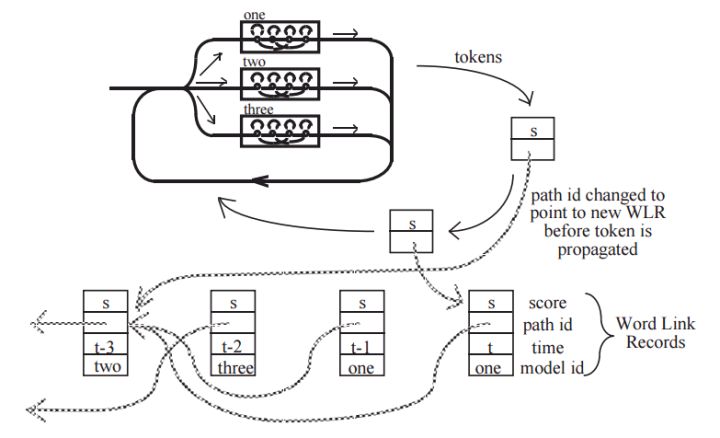
7. HTK开源工具包实现了搭建完整语音识别系统各个环节:录制数据,标注文件,模型初始化与参数学习,以及解码识别,支持语言模型n-gram和RNNLM,实现GPU加速,极大地提高了迭代效率。美中不足的是,目前仅支持前馈型神经网络模型,而且版本更新越来越慢。
8. HTK的历史一览,曾被微软公司收购,最终又回归剑桥大学。从版本更新可知语音识别技术的历史(深度 | 四十年的难题与荣耀–从历史视角看语音识别发展)发展进程。在引入深度学习以前(Hinton 2009),HTK紧跟技术潮流。

第二部分 语音识别概念
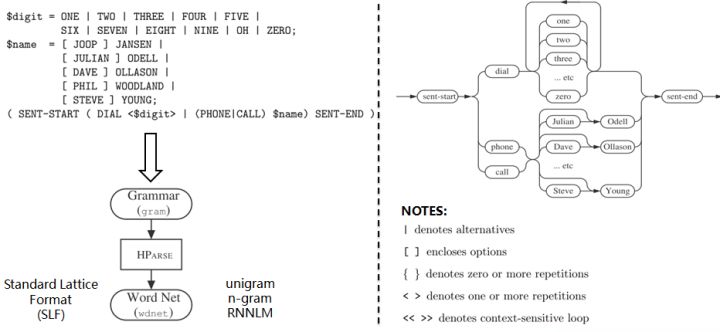
9. Grammar:HParse可以将语法规则(类似于正则表达式的概念)展开成词网络(Word Network),也称词图(Lattice),即限制语音识别的路径,无论什么数据的识别结果都必然是词网络中的一条路径。词网络起到了语言模型的作用;在大规模数据集上,可以被n-gram和RNNLM模型代替。
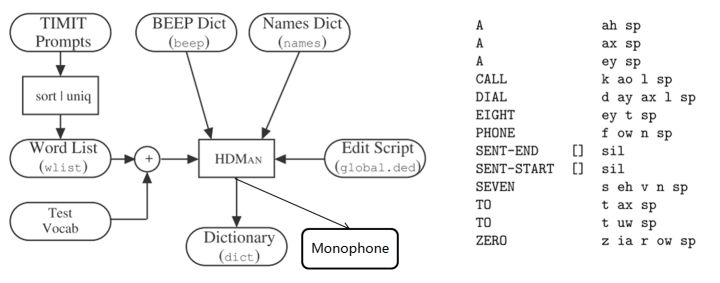
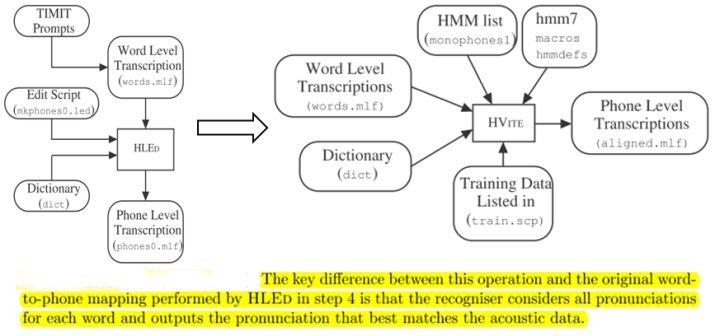
10. Dictionary: HDMan根据完整的发音字典、词网络中的词以及特定任务中的特定词,生成具体任务的词典和音素表(如果对单音素建模,音素数等于模型数)。如果是对音素建模,首先识别出状态,再根据状态路径的联合概率值识别出音素,音素查找字典组合成单词,单词参考语言模型连接成句子,找到最为匹配的词序作为输出结果。
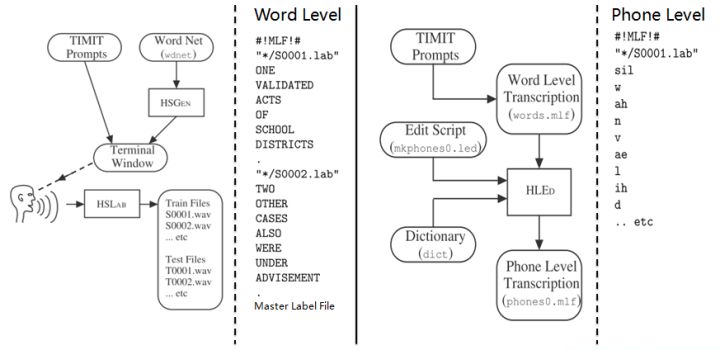
11. Transcription: 根据词网络可以按需生成标注样本,根据样本采集语音数据。HLEd可以根据字典将词级别的标注文件转换成音素级别的标注,完成处理的数据,可以进一步提取特征或转化成语谱图作为声学模型的输入。
12. Feature: HCopy根据配置文件对音频信号提取特征,常用的有MFCC,即Mel频率倒谱系数。更多语音特征提取参见语音识别特征提取。
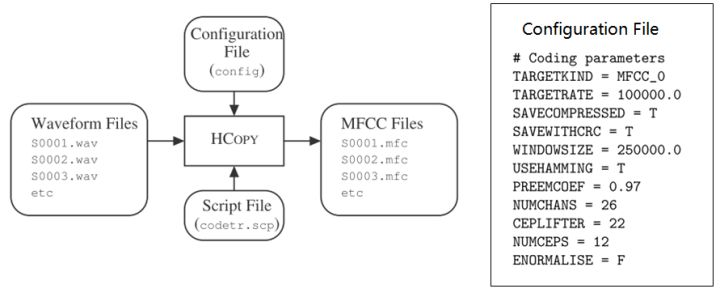
13. Training Monophone HMMs: HERest采用处理后的标注数据,根据最大似然(ML)准则,迭代音素文件列表中枚举的模型,直至收敛。其中HCompv采用所有训练样本的均值和方差来初始化GMM的策略,训练数据可以不带标签,非监督初始化。
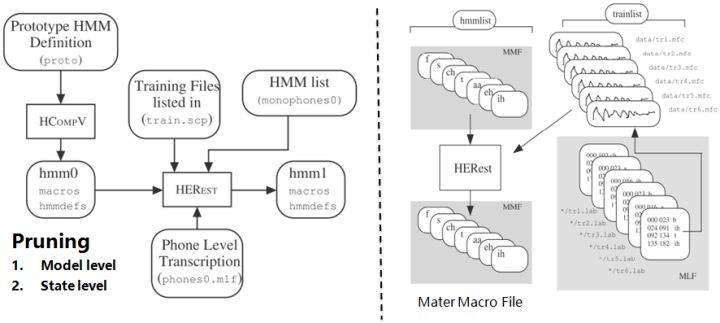
为了提高迭代效率和排除错误标注数据的影响,参数学习过程中需要裁剪,分为状态级别裁剪或模型级别约束,即定向搜索beam search,按规则约束搜索范围。

14. Realigning: 基于Viterbi算法的帧层次对齐操作,可以纠正偏差的语音标注,生成带时间戳的标注文本,用来再迭代训练模型,提高训练准确率。
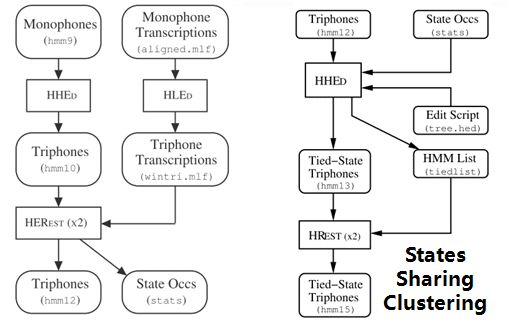
15. Triphones HMMs: 基于单音素模型可以构造三音素模型,在音素级别可以利用更多的上下文信息,同时也意味着模型数量的增加。这时需要状态共享和状态聚类技术,降低模型的参数,提高训练效率。

16. Discriminative Training: 模型最大似然输出的结果,根据最大互信息(MMI)和最小音素错误率(WPE)两种训练准则,进一步调整HMM模型的参数,降低识别错误率。HInit利用带标签的语音数据来初始化,并基于Viterbi算法再生成标注文件迭代数次训练模型。
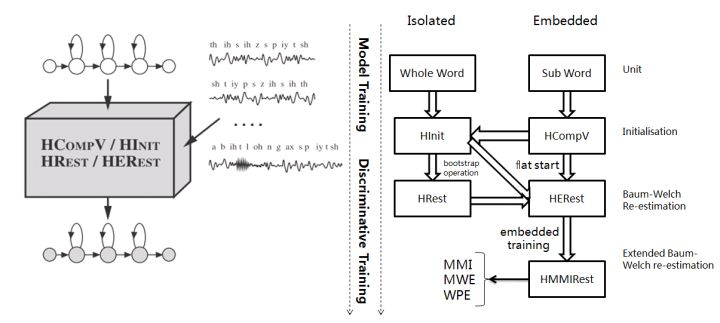
判别性训练的详细参考步骤:
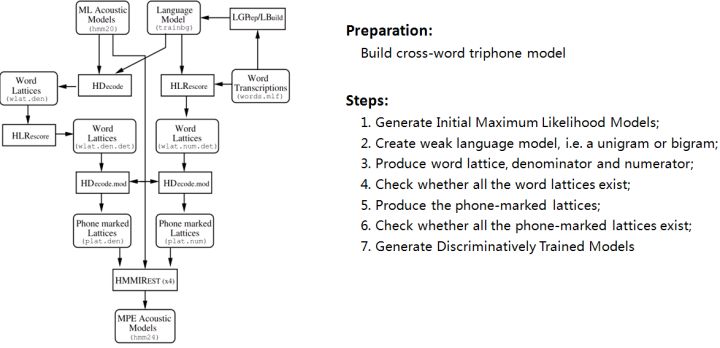
判别性训练,HDecode解码器和DNN-HMM模型等大规模连续词汇识别技术都是基于跨词模式。词内模式的三音素不能跨词连接,因此利用较少的上下文信息,识别性能也较跨词模型差。
17. DNN:之后将近20年,语音识别技术的发展比较缓慢;直至2009年,Hinton将DNN应用于声学建模,并在TIMIT数据集上获得了当时最低的词错率。随着GPU的普及,加速了DNN的发展。采用DNN替换GMM对HMM状态的发射概率进行建模有两大优点:一是不需要对语音数据分布进行假设,不需要切分成stream来分段拟合;DNN的输入可以将相邻语音帧拼接成包含时序结构信息的矢量,在帧层次利用更多的上下文信息。HTK支持基于帧和序列两种训练DNN-HMM模型的方式。


更多参见L09-DNN-Acoustic-Modeling。
18. Decoder: HVite根据声学模型、语言模型和字典识别未知语音,并用HResults来统计分析识别准确率。此外,HTK还支持大规模连续词汇的解码工具HDecode,可以融合更加复杂的语言模型,如3-gram和Recurrent Neural Network Language Models。为了提高识别效率,解码器也支持裁剪,Beam Search。
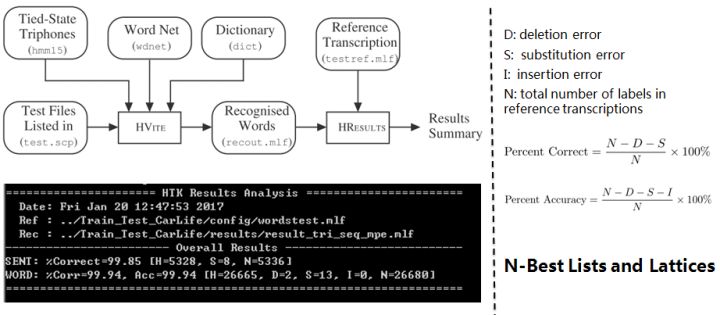
——————————————————————————————————————–
以上分析可知,基于HMM的模型训练需要经过很多细致的步骤,从数据处理及特征提取,到模型初始化,从单音素到三音素的训练和解码,从基于最大似然的训练到基于最大互信息的判别性训练,以及大量的配置文件,需要很高的学习时间成本;为了获得比较好得识别准确率,还需要对齐操作。深度学习的兴起,从开始用DNN代替GMM,发展到现在复杂的LSTM和Deep CNN模型,结合CTC目标函数,甚至attention机制,带来了基于end-to-end的方法,把中间的一些需要人工做的步骤或者需要预处理的部分去掉。
最后,基于Tensorflow实现端到端的Wavenet做中文语音识别。
打赏作者

近期评论