
stable-diffusion
先放GIT地址:
https://github.com/CompVis/stable-diffusion
一. 简介Stable Diffusion
Stable Diffusion是一种扩散模型(diffusion model)。扩散模型是在2015年推出的,其目的是消除对训练图像的连续应用高斯噪声,可以将其视为一系列去噪自编码器。它使用了一种被称为“潜在扩散模型”(latent diffusion model; LDM)的变体。与其学习去噪图像数据(在“像素空间”中),而是训练自动编码器将图像转换为低维潜在空间。添加和去除噪声的过程被应用于这个潜在表示,然后将最终的去噪输出解码到像素空间中。每个去噪步骤都由一个U-Net架构完成。研究人员指出,降低训练和生成的计算要求是LDM的一个优势。
去噪步骤可以以文本串、图像或一些其他数据为条件。调节数据的编码通过交叉注意机制(cross-attention mechanism)暴露给去噪U-Net的架构。为了对文本进行调节,一个Transformer模型被训练来对提示词进行编码。
用法:
Stable Diffusion模型支持通过使用提示词来产生新的图像,描述要包含或省略的元素。以及重新绘制现有的图像,其中包含提示词中描述的新元素(该过程通常被称为“指导性图像合成”(guided image synthesis)通过使用模型的扩散去噪机制(diffusion-denoising mechanism)。此外,该模型还允许通过提示词在现有的图中进内联补绘制和外补绘制来部分更改,当与支持这种功能的用户界面使用时,其中存在许多不同的开源软件。
**注意:VRAM较少的用户可以选择以float16的精度加载权重,而不是默认的float32,以降低VRAM使用率
软件:Ubuntu 16.04
CUDA 11.6 GCC-9.4
安装及环境搭建:
1.安装conda ,安装外部依赖环境CUDA
详细参照http://www.machine-kernel.cn/archives/ubuntu1604nvidia-gpu
2.创建虚拟环境,基于PYTHON3.8.5版本创建
3.安装pytorch环境,模型选用
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
sd-v1-4.ckpt: Resumed from sd-v1-2.ckpt. 225k steps at resolution 512×512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning to improve classifier-free guidance sampling.
- Hardware: 32 x 8 x A100 GPUs
- Optimizer: AdamW
- Gradient Accumulations: 2
- Batch: 32 x 8 x 2 x 4 = 2048
- Learning rate: warmup to 0.0001 for 10,000 steps and then kept constant
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
模型下载地址 :
https://huggingface.co/CompVis
4.运行
python ./scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms --H 512 --W 512 --n_samples 8
问题:
File "/home/xxx/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 688, in <lambda>
return self._apply(lambda t: t.cuda(device))
File "/home/xxx/envs/ldm/lib/python3.8/site-packages/torch/cuda/__init__.py", line 216, in _lazy_init
torch._C._cuda_init()
RuntimeError: CUDA driver initialization failed, you might not have a CUDA gpu.
CUDA环境存一定的问题,CUDA版本与TORCH版本不对应
测试代码
import torch
print(torch.cuda.is_available())
print(torch.__version__)
2.提示
CUDA版本不对
GCC版本不对
创建PYTHON 3.8的虚拟环境后,再次将虚拟环境激活,在虚拟环境中创建:
conda activate py3.8
conda env create -f environment.yaml
conda activate ldm
3.其它问题
提示各MODULE模块不存在,或者导入异常,出现CONDA无法安装时用PIP进行安装
pip install xxx -i https://...........................................
4.运行
下载模型,V1.4
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
python ./scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms

GPU的显存不够,改变小生成图像,并且降低 n_samples
python ./scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
--H 256 --W 256 --n_samples 1
5
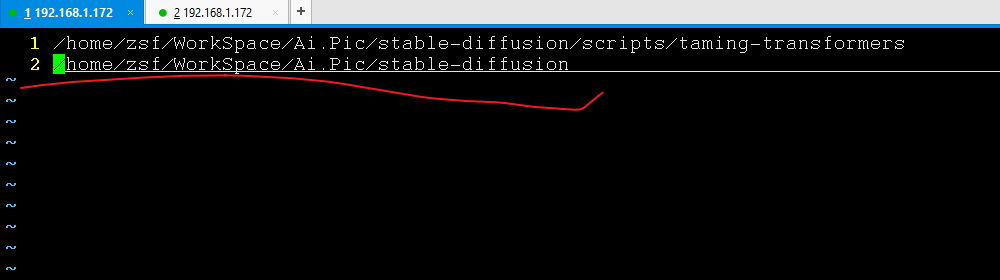
AttributeError: type object 'BasicTransformerBlock' has no attribute 'ATTENTION_MODES'
删除下面文件中划红线的那一行
vim /home/zsf/anaconda2/envs/ldm/lib/python3.8/site-packages/easy-install.pth
6.提示缺少LDM
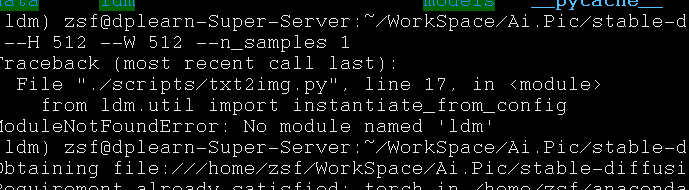
再次安装LDM, LDM指—-latent-diffusion,不要用pip install ldm
pip install -e .
二. 文生图
Stable Diffusion中的文生图采样脚本,称为”txt2img”,接受一个提示词,以及包括采样器(sampling type),图像尺寸,和随机种子的各种选项参数,并根据模型对提示的解释生成一个图像文件。 生成的图像带有不可见的数字水印标签,以允许用户识别由Stable Diffusion生成的图像,尽管如果图像被调整大小或旋转,该水印将失去其有效性。Stable Diffusion模型是在由512×512分辨率图像组成的数据集上训练出来的,这意味着txt2img生成图像的最佳配置也是以512×512的分辨率生成的,偏离这个大小会导致生成输出质量差。
每一个txt2img的生成过程都会涉及到一个影响到生成图像的随机种子;用户可以选择随机化种子以探索不同生成结果,或者使用相同的种子来获得与之前生成的图像相同的结果。用户还可以调整采样迭代步数(inference steps);较高的值需要较长的运行时间,但较小的值可能会导致视觉缺陷。另一个可配置的选项,即无分类指导比例值,允许用户调整提示词的相关性(classifier-free guidance scale value);更具实验性或创造性的用例可以选择较低的值,而旨在获得更具体输出的用例可以使用较高的值。
反向提示词(negative prompt)是包含在Stable Diffusion的一些用户界面软件中的一个功能,它允许用户指定模型在图像生成过程中应该避免的提示,适用于由于用户提供的普通提示词,或者由于模型最初的训练,造成图像输出中出现不良的图像特征。与使用强调符(emphasis marker)相比,使用反向提示词在降低生成不良的图像的频率方面具有高度统计显著的效果;强调符是另一种为提示的部分增加权重的方法,被一些Stable Diffusion的开源实现所利用,在关键词中加入括号以增加或减少强调
python ./scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --H 640 --W 640 --n_samples 1 --scale 5

import argparse, os, sys, glob
import cv2
import torch
import numpy as np
from omegaconf import OmegaConf
from PIL import Image
from tqdm import tqdm, trange
from imwatermark import WatermarkEncoder
from itertools import islice
from einops import rearrange
from torchvision.utils import make_grid
import time
from pytorch_lightning import seed_everything
from torch import autocast
from contextlib import contextmanager, nullcontext
from ldm.util import instantiate_from_config
from ldm.models.diffusion.ddim import DDIMSampler
from ldm.models.diffusion.plms import PLMSSampler
from ldm.models.diffusion.dpm_solver import DPMSolverSampler
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from transformers import AutoFeatureExtractor
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:128"
# load safety model
safety_model_id = "CompVis/stable-diffusion-safety-checker"
safety_feature_extractor = AutoFeatureExtractor.from_pretrained(safety_model_id)
safety_checker = StableDiffusionSafetyChecker.from_pretrained(safety_model_id)
def chunk(it, size):
it = iter(it)
return iter(lambda: tuple(islice(it, size)), ())
def numpy_to_pil(images):
"""
Convert a numpy image or a batch of images to a PIL image.
"""
if images.ndim == 3:
images = images[None, ...]
images = (images * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
return pil_images
def load_model_from_config(config, ckpt, verbose=False):
print(f"Loading model from {ckpt}")
pl_sd = torch.load(ckpt, map_location="cpu")
if "global_step" in pl_sd:
print(f"Global Step: {pl_sd['global_step']}")
sd = pl_sd["state_dict"]
model = instantiate_from_config(config.model)
m, u = model.load_state_dict(sd, strict=False)
if len(m) > 0 and verbose:
print("missing keys:")
print(m)
if len(u) > 0 and verbose:
print("unexpected keys:")
print(u)
model.cuda()
model.eval()
return model
def put_watermark(img, wm_encoder=None):
if wm_encoder is not None:
img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
img = wm_encoder.encode(img, 'dwtDct')
img = Image.fromarray(img[:, :, ::-1])
return img
def load_replacement(x):
try:
hwc = x.shape
y = Image.open("assets/rick.jpeg").convert("RGB").resize((hwc[1], hwc[0]))
y = (np.array(y)/255.0).astype(x.dtype)
assert y.shape == x.shape
return y
except Exception:
return x
def check_safety(x_image):
safety_checker_input = safety_feature_extractor(numpy_to_pil(x_image), return_tensors="pt")
x_checked_image, has_nsfw_concept = safety_checker(images=x_image, clip_input=safety_checker_input.pixel_values)
assert x_checked_image.shape[0] == len(has_nsfw_concept)
for i in range(len(has_nsfw_concept)):
if has_nsfw_concept[i]:
x_checked_image[i] = load_replacement(x_checked_image[i])
return x_checked_image, has_nsfw_concept
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"--prompt",
type=str,
nargs="?",
default="a painting of a virus monster playing guitar",
help="the prompt to render"
)
parser.add_argument(
"--outdir",
type=str,
nargs="?",
help="dir to write results to",
default="outputs/txt2img-samples"
)
parser.add_argument(
"--skip_grid",
action='store_true',
help="do not save a grid, only individual samples. Helpful when evaluating lots of samples",
)
parser.add_argument(
"--skip_save",
action='store_true',
help="do not save individual samples. For speed measurements.",
)
parser.add_argument(
"--ddim_steps",
type=int,
default=50,
help="number of ddim sampling steps",
)
parser.add_argument(
"--plms",
action='store_true',
help="use plms sampling",
)
parser.add_argument(
"--dpm_solver",
action='store_true',
help="use dpm_solver sampling",
)
parser.add_argument(
"--laion400m",
action='store_true',
help="uses the LAION400M model",
)
parser.add_argument(
"--fixed_code",
action='store_true',
help="if enabled, uses the same starting code across samples ",
)
parser.add_argument(
"--ddim_eta",
type=float,
default=0.0,
help="ddim eta (eta=0.0 corresponds to deterministic sampling",
)
parser.add_argument(
"--n_iter",
type=int,
default=2,
help="sample this often",
)
parser.add_argument(
"--H",
type=int,
default=512,
help="image height, in pixel space",
)
parser.add_argument(
"--W",
type=int,
default=512,
help="image width, in pixel space",
)
parser.add_argument(
"--C",
type=int,
default=4,
help="latent channels",
)
parser.add_argument(
"--f",
type=int,
default=8,
help="downsampling factor",
)
parser.add_argument(
"--n_samples",
type=int,
default=3,
help="how many samples to produce for each given prompt. A.k.a. batch size",
)
parser.add_argument(
"--n_rows",
type=int,
default=0,
help="rows in the grid (default: n_samples)",
)
parser.add_argument(
"--scale",
type=float,
default=7.5,
help="unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))",
)
parser.add_argument(
"--from-file",
type=str,
help="if specified, load prompts from this file",
)
parser.add_argument(
"--config",
type=str,
default="configs/stable-diffusion/v1-inference.yaml",
help="path to config which constructs model",
)
parser.add_argument(
"--ckpt",
type=str,
default="models/ldm/stable-diffusion-v1/model.ckpt",
help="path to checkpoint of model",
)
parser.add_argument(
"--seed",
type=int,
default=42,
help="the seed (for reproducible sampling)",
)
parser.add_argument(
"--precision",
type=str,
help="evaluate at this precision",
choices=["full", "autocast"],
default="autocast"
)
opt = parser.parse_args()
if opt.laion400m:
print("Falling back to LAION 400M model...")
opt.config = "configs/latent-diffusion/txt2img-1p4B-eval.yaml"
opt.ckpt = "models/ldm/text2img-large/model.ckpt"
opt.outdir = "outputs/txt2img-samples-laion400m"
seed_everything(opt.seed)
config = OmegaConf.load(f"{opt.config}")
model = load_model_from_config(config, f"{opt.ckpt}")
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model = model.to(device)
if opt.dpm_solver:
sampler = DPMSolverSampler(model)
elif opt.plms:
sampler = PLMSSampler(model)
else:
sampler = DDIMSampler(model)
os.makedirs(opt.outdir, exist_ok=True)
outpath = opt.outdir
print("Creating invisible watermark encoder (see https://github.com/ShieldMnt/invisible-watermark)...")
wm = "StableDiffusionV1"
wm_encoder = WatermarkEncoder()
wm_encoder.set_watermark('bytes', wm.encode('utf-8'))
batch_size = opt.n_samples
n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
if not opt.from_file:
prompt = opt.prompt
assert prompt is not None
data = [batch_size * [prompt]]
else:
print(f"reading prompts from {opt.from_file}")
with open(opt.from_file, "r") as f:
data = f.read().splitlines()
data = list(chunk(data, batch_size))
sample_path = os.path.join(outpath, "samples")
os.makedirs(sample_path, exist_ok=True)
base_count = len(os.listdir(sample_path))
grid_count = len(os.listdir(outpath)) - 1
start_code = None
if opt.fixed_code:
start_code = torch.randn([opt.n_samples, opt.C, opt.H // opt.f, opt.W // opt.f], device=device)
precision_scope = autocast if opt.precision=="autocast" else nullcontext
with torch.no_grad():
with precision_scope("cuda"):
with model.ema_scope():
tic = time.time()
all_samples = list()
for n in trange(opt.n_iter, desc="Sampling"):
for prompts in tqdm(data, desc="data"):
uc = None
if opt.scale != 1.0:
uc = model.get_learned_conditioning(batch_size * [""])
if isinstance(prompts, tuple):
prompts = list(prompts)
c = model.get_learned_conditioning(prompts)
shape = [opt.C, opt.H // opt.f, opt.W // opt.f]
samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
conditioning=c,
batch_size=opt.n_samples,
shape=shape,
verbose=False,
unconditional_guidance_scale=opt.scale,
unconditional_conditioning=uc,
eta=opt.ddim_eta,
x_T=start_code)
x_samples_ddim = model.decode_first_stage(samples_ddim)
x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
x_samples_ddim = x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy()
x_checked_image, has_nsfw_concept = check_safety(x_samples_ddim)
x_checked_image_torch = torch.from_numpy(x_checked_image).permute(0, 3, 1, 2)
if not opt.skip_save:
for x_sample in x_checked_image_torch:
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
img = Image.fromarray(x_sample.astype(np.uint8))
img = put_watermark(img, wm_encoder)
img.save(os.path.join(sample_path, f"{base_count:05}.png"))
base_count += 1
if not opt.skip_grid:
all_samples.append(x_checked_image_torch)
if not opt.skip_grid:
# additionally, save as grid
grid = torch.stack(all_samples, 0)
grid = rearrange(grid, 'n b c h w -> (n b) c h w')
grid = make_grid(grid, nrow=n_rows)
# to image
grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
img = Image.fromarray(grid.astype(np.uint8))
img = put_watermark(img, wm_encoder)
img.save(os.path.join(outpath, f'grid-{grid_count:04}.png'))
grid_count += 1
toc = time.time()
print(f"Your samples are ready and waiting for you here: \n{outpath} \n"
f" \nEnjoy.")
if __name__ == "__main__":
main()三. 图生图
Stable Diffusion包括另一个取样脚本,称为”img2img”,它接受一个提示词、现有图像的文件路径和0.0到1.0之间的去噪强度,并在原始图像的基础上产生一个新的图像,该图像也具有提示词中提供的元素;去噪强度表示添加到输出图像的噪声量,值越大,图像变化越多,但在语义上可能与提供的提示不一致。 图像升频是img2img的一个潜在用例,除此之外。
内补绘制与外补绘制
Stable Diffusion模型的许多不同用户界面软件提供了通过img2img进行图生图的其他用例。内补绘制(inpainting)由用户提供的蒙版描绘的现有图像的一部分,根据所提供的提示词,用新生成的内容填充蒙版的空间。 相反,外补绘制(outpainting)将图像扩展到其原始尺寸之外,用根据所提供的提示词生成的内容来填补以前的空白空间。
"""make variations of input image"""
import argparse, os, sys, glob
import PIL
import torch
import numpy as np
from omegaconf import OmegaConf
from PIL import Image
from tqdm import tqdm, trange
from itertools import islice
from einops import rearrange, repeat
from torchvision.utils import make_grid
from torch import autocast
from contextlib import nullcontext
import time
from pytorch_lightning import seed_everything
from ldm.util import instantiate_from_config
from ldm.models.diffusion.ddim import DDIMSampler
from ldm.models.diffusion.plms import PLMSSampler
def chunk(it, size):
it = iter(it)
return iter(lambda: tuple(islice(it, size)), ())
def load_model_from_config(config, ckpt, verbose=False):
print(f"Loading model from {ckpt}")
pl_sd = torch.load(ckpt, map_location="cpu")
if "global_step" in pl_sd:
print(f"Global Step: {pl_sd['global_step']}")
sd = pl_sd["state_dict"]
model = instantiate_from_config(config.model)
m, u = model.load_state_dict(sd, strict=False)
if len(m) > 0 and verbose:
print("missing keys:")
print(m)
if len(u) > 0 and verbose:
print("unexpected keys:")
print(u)
model.cuda()
model.eval()
return model
def load_img(path):
image = Image.open(path).convert("RGB")
w, h = image.size
print(f"loaded input image of size ({w}, {h}) from {path}")
w, h = map(lambda x: x - x % 32, (w, h)) # resize to integer multiple of 32
image = image.resize((w, h), resample=PIL.Image.LANCZOS)
image = np.array(image).astype(np.float32) / 255.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
return 2.*image - 1.
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"--prompt",
type=str,
nargs="?",
default="a painting of a virus monster playing guitar",
help="the prompt to render"
)
parser.add_argument(
"--init-img",
type=str,
nargs="?",
help="path to the input image"
)
parser.add_argument(
"--outdir",
type=str,
nargs="?",
help="dir to write results to",
default="outputs/img2img-samples"
)
parser.add_argument(
"--skip_grid",
action='store_true',
help="do not save a grid, only individual samples. Helpful when evaluating lots of samples",
)
parser.add_argument(
"--skip_save",
action='store_true',
help="do not save indiviual samples. For speed measurements.",
)
parser.add_argument(
"--ddim_steps",
type=int,
default=50,
help="number of ddim sampling steps",
)
parser.add_argument(
"--plms",
action='store_true',
help="use plms sampling",
)
parser.add_argument(
"--fixed_code",
action='store_true',
help="if enabled, uses the same starting code across all samples ",
)
parser.add_argument(
"--ddim_eta",
type=float,
default=0.0,
help="ddim eta (eta=0.0 corresponds to deterministic sampling",
)
parser.add_argument(
"--n_iter",
type=int,
default=1,
help="sample this often",
)
parser.add_argument(
"--C",
type=int,
default=4,
help="latent channels",
)
parser.add_argument(
"--f",
type=int,
default=8,
help="downsampling factor, most often 8 or 16",
)
parser.add_argument(
"--n_samples",
type=int,
default=2,
help="how many samples to produce for each given prompt. A.k.a batch size",
)
parser.add_argument(
"--n_rows",
type=int,
default=0,
help="rows in the grid (default: n_samples)",
)
parser.add_argument(
"--scale",
type=float,
default=5.0,
help="unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))",
)
parser.add_argument(
"--strength",
type=float,
default=0.75,
help="strength for noising/unnoising. 1.0 corresponds to full destruction of information in init image",
)
parser.add_argument(
"--from-file",
type=str,
help="if specified, load prompts from this file",
)
parser.add_argument(
"--config",
type=str,
default="configs/stable-diffusion/v1-inference.yaml",
help="path to config which constructs model",
)
parser.add_argument(
"--ckpt",
type=str,
default="models/ldm/stable-diffusion-v1/model.ckpt",
help="path to checkpoint of model",
)
parser.add_argument(
"--seed",
type=int,
default=42,
help="the seed (for reproducible sampling)",
)
parser.add_argument(
"--precision",
type=str,
help="evaluate at this precision",
choices=["full", "autocast"],
default="autocast"
)
opt = parser.parse_args()
seed_everything(opt.seed)
config = OmegaConf.load(f"{opt.config}")
model = load_model_from_config(config, f"{opt.ckpt}")
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model = model.to(device)
if opt.plms:
raise NotImplementedError("PLMS sampler not (yet) supported")
sampler = PLMSSampler(model)
else:
sampler = DDIMSampler(model)
os.makedirs(opt.outdir, exist_ok=True)
outpath = opt.outdir
batch_size = opt.n_samples
n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
if not opt.from_file:
prompt = opt.prompt
assert prompt is not None
data = [batch_size * [prompt]]
else:
print(f"reading prompts from {opt.from_file}")
with open(opt.from_file, "r") as f:
data = f.read().splitlines()
data = list(chunk(data, batch_size))
sample_path = os.path.join(outpath, "samples")
os.makedirs(sample_path, exist_ok=True)
base_count = len(os.listdir(sample_path))
grid_count = len(os.listdir(outpath)) - 1
assert os.path.isfile(opt.init_img)
init_image = load_img(opt.init_img).to(device)
init_image = repeat(init_image, '1 ... -> b ...', b=batch_size)
init_latent = model.get_first_stage_encoding(model.encode_first_stage(init_image)) # move to latent space
sampler.make_schedule(ddim_num_steps=opt.ddim_steps, ddim_eta=opt.ddim_eta, verbose=False)
assert 0. <= opt.strength <= 1., 'can only work with strength in [0.0, 1.0]'
t_enc = int(opt.strength * opt.ddim_steps)
print(f"target t_enc is {t_enc} steps")
precision_scope = autocast if opt.precision == "autocast" else nullcontext
with torch.no_grad():
with precision_scope("cuda"):
with model.ema_scope():
tic = time.time()
all_samples = list()
for n in trange(opt.n_iter, desc="Sampling"):
for prompts in tqdm(data, desc="data"):
uc = None
if opt.scale != 1.0:
uc = model.get_learned_conditioning(batch_size * [""])
if isinstance(prompts, tuple):
prompts = list(prompts)
c = model.get_learned_conditioning(prompts)
# encode (scaled latent)
z_enc = sampler.stochastic_encode(init_latent, torch.tensor([t_enc]*batch_size).to(device))
# decode it
samples = sampler.decode(z_enc, c, t_enc, unconditional_guidance_scale=opt.scale,
unconditional_conditioning=uc,)
x_samples = model.decode_first_stage(samples)
x_samples = torch.clamp((x_samples + 1.0) / 2.0, min=0.0, max=1.0)
if not opt.skip_save:
for x_sample in x_samples:
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
Image.fromarray(x_sample.astype(np.uint8)).save(
os.path.join(sample_path, f"{base_count:05}.png"))
base_count += 1
all_samples.append(x_samples)
if not opt.skip_grid:
# additionally, save as grid
grid = torch.stack(all_samples, 0)
grid = rearrange(grid, 'n b c h w -> (n b) c h w')
grid = make_grid(grid, nrow=n_rows)
# to image
grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
Image.fromarray(grid.astype(np.uint8)).save(os.path.join(outpath, f'grid-{grid_count:04}.png'))
grid_count += 1
toc = time.time()
print(f"Your samples are ready and waiting for you here: \n{outpath} \n"
f" \nEnjoy.")
if __name__ == "__main__":
main()web版本:
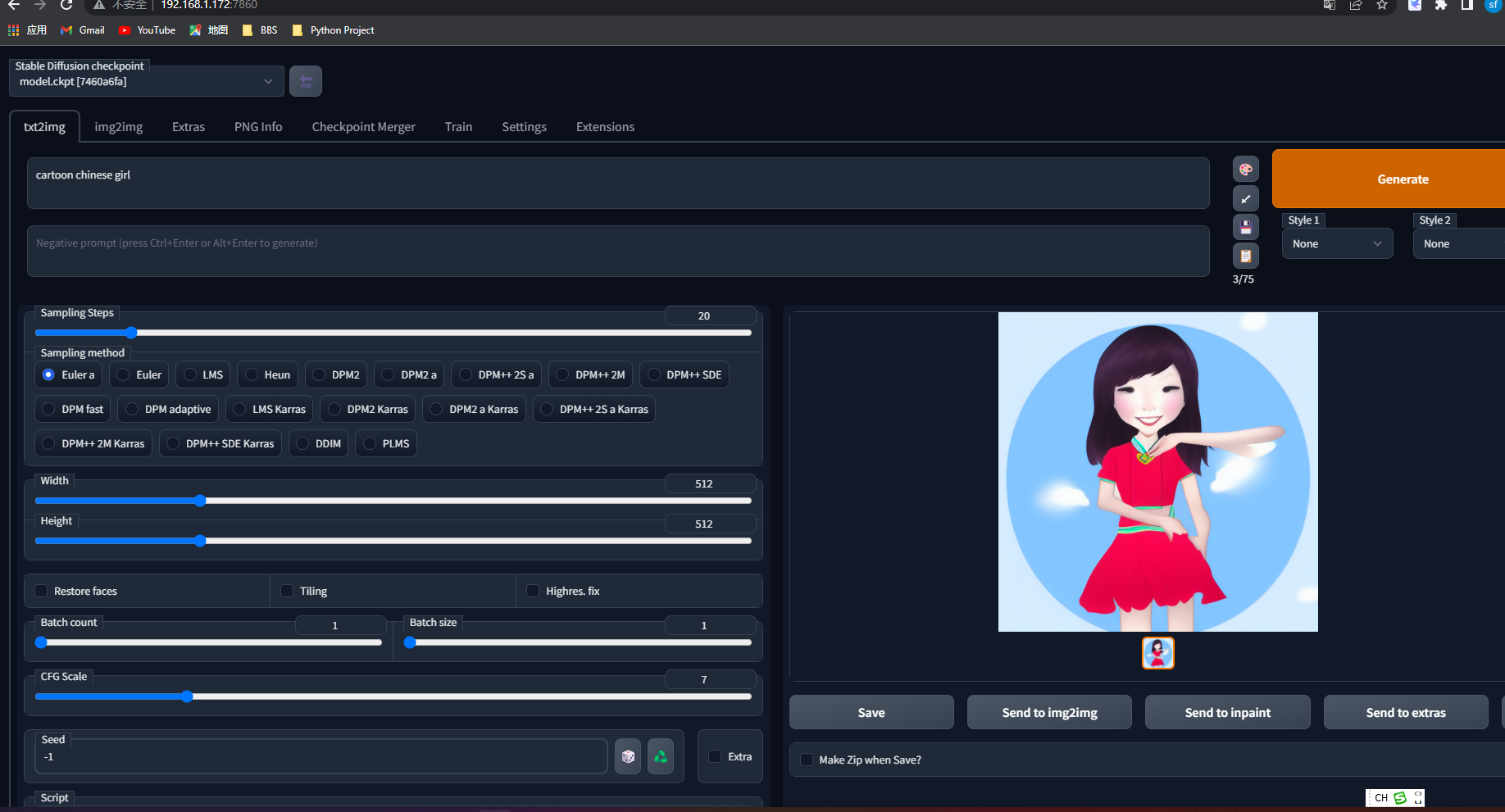
安装:
“`
# install torch with CUDA support. See https://pytorch.org/get-started/locally/ for more instructions if this fails.
pip install torch –extra-index-url https://download.pytorch.org/whl/cu113
# check if torch supports GPU; this must output "True". You need CUDA 11. installed for this. You might be able to use
# a different version, but this is what I tested.
python -c "import torch; print(torch.cuda.is_available())"
# clone web ui and go into its directory
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui
# clone repositories for Stable Diffusion and (optionally) CodeFormer
mkdir repositories
git clone https://github.com/CompVis/stable-diffusion.git repositories/stable-diffusion
git clone https://github.com/CompVis/taming-transformers.git repositories/taming-transformers
git clone https://github.com/sczhou/CodeFormer.git repositories/CodeFormer
git clone https://github.com/salesforce/BLIP.git repositories/BLIP
# install requirements of Stable Diffusion
pip install transformers==4.19.2 diffusers invisible-watermark --prefer-binary
# install k-diffusion
pip install git+https://github.com/crowsonkb/k-diffusion.git --prefer-binary
# (optional) install GFPGAN (face restoration)
pip install git+https://github.com/TencentARC/GFPGAN.git --prefer-binary
# (optional) install requirements for CodeFormer (face restoration)
pip install -r repositories/CodeFormer/requirements.txt --prefer-binary
# install requirements of web ui
pip install -r requirements.txt --prefer-binary
# update numpy to latest version
pip install -U numpy --prefer-binary
# (outside of command line) put stable diffusion model into web ui directory
# the command below must output something like: 1 File(s) 4,265,380,512 bytes
dir model.ckpt
'''```



近期评论